Why is everyone reading Sapiens?
15 Jan 2017With my twitter feed talking about books this December, I was struck by how popular Sapiens: A Brief History of Humankind was. These weren't people who exchange book recommendations with each other, so there had to be an external cause to this. And Sapiens is not a recent popular release like Michael Lewis' The Undoing Project that I would expect to be universally popular at launch.
So I spent some time trying to figure out what happened. I'm left with some understanding of how book sales - unlike movies - are driven mostly by big names. My initial hypothesis was that the book probably featured in Bill Gates' yearly book list, but that was easy to (in)validate. (Gates did review the book on his blog last year, but it doesn't look like that contributed to the book's success in December.) My best guess to why the book took off is: Obama.
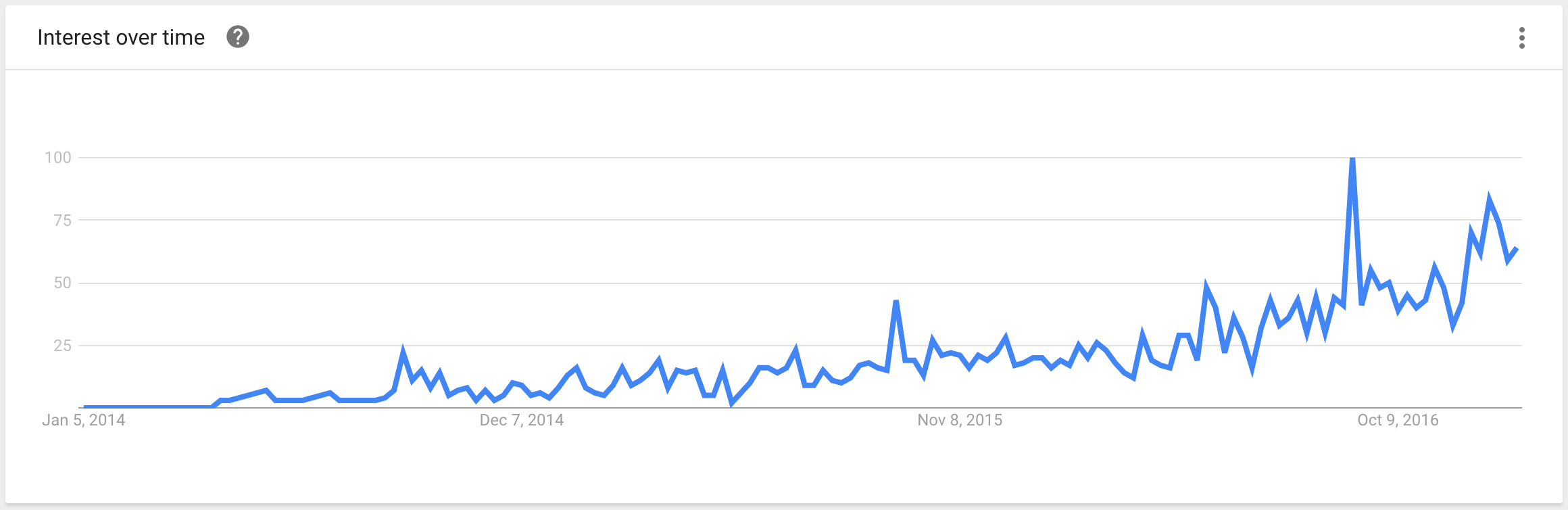
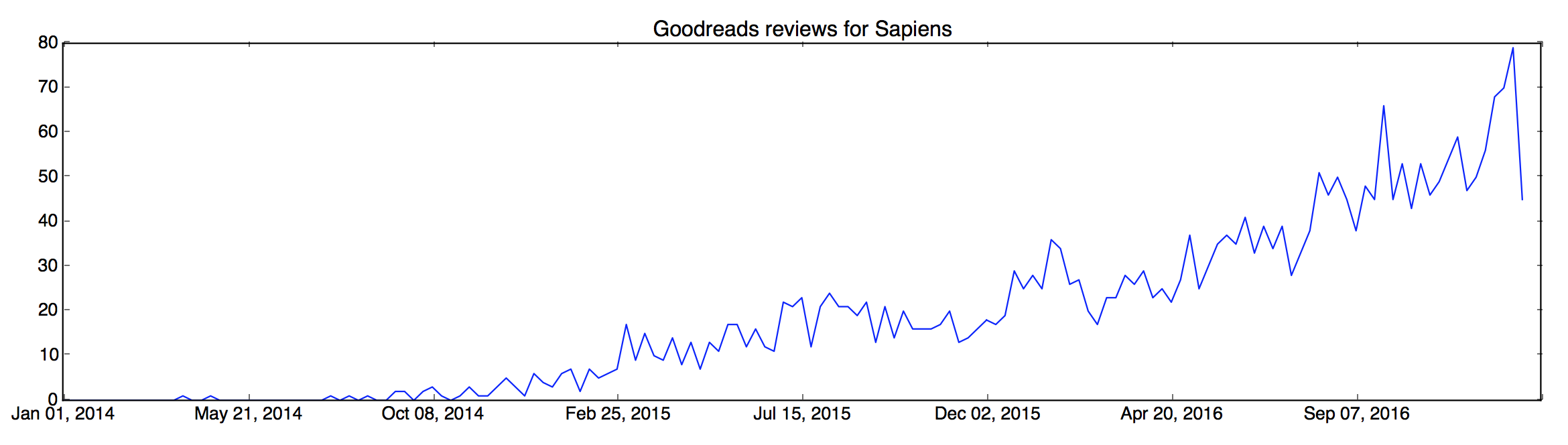
For my conclusions I used a few data sources: Google trends, which represents a general awareness/curiosity about the book, Goodreads reviews, which represent the book's popularity in a more relevant audience, and a timeline of relevant events.
Relevant events
- 2011: Sapiens launched in Hebrew
- August 2014: Yuval Harari's Coursera mooc on the history of mankind starts
- Mid-2014: English translation of Sapiens released, with normal set of book reviews
- June 2015: Yuval Harari gives a TED talk
- May 17, 2016: Bill Gates reviews Sapiens
- July 18, 2016: I added Sapiens to my to-read bookshelf on Goodreads - turns out a friend had finished reading it on the same day (who might have read Gates?)
- September 4, 2016: Obama recommends Sapiens on CNN
- September 8, 2016: Harari's new book Homo Deus is released
The last two events coincide with the peak in the Google trends graph, and it would be safe to say that Obama on CNN would have more weightage than a new book (considering how insignificant book launches seem to be on these scales). The Goodreads reviews peak trails the Google trends peak by a few months, which I believe can be explained by the time it would take for people to getting to read it + the holiday season for relaxed reading.
Appendix
Book popularity APIs are hard. I thought the Goodreads API doc would give me the popularity data I wanted, but there is no API for that objective. What I ended up doing was scraping reviews from their reviews widget, and Beautiful Soup made it easy.
def get_raw_dates_from_url(url):
r = urllib.urlopen(url).read()
soup = BeautifulSoup(r)
raw_dates = soup.find_all('span', class_='gr_review_date')
return raw_dates